
Gradient descent is an algorithm for finding the local minimum of a differentiable function and is used in most machine learning algorithms.
In linear regression, we had the following minimization problem

where 

used in multiple linear regression. We can minimize any (well defined) function using gradient descent. The goal is to minimize the error above (to get the line which best fits the data) and for that, we will use the gradient which will point us in the ‘right’ direction towards the minimum.
Gradient descent is an optimization algorithm. It starts with some 

As a derivative, gradient also represents a slope of the tangent of the graph of a function. Gradient can be seen as a change in a function when vector 
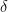



Here 
In this case, the gradient points along the direction in which the function increases most rapidly. This is the process of maximizing the function and we call this process the gradient ascent.
In gradient descent, we are interested in minimization instead of the maximization. We want the fastest way to reach the minimum. Similarly, as above, the gradient will point along the direction in which the function decreases most rapidly – in the negative gradient direction.
In this case we have

Now we can guess 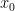

We can now apply this now to the linear regression.
If we substitute the formula for linear regression and divide by average for simplicity and take the partial derivative, we get


Now we can run this simultaneously in iterations and in every iteration, we will get the line that has a smaller error than in the previous iteration and we will eventually reach the minimum.
Resources:
