
Problem description
We have CSV file containing information about 50 companies. Your job as a data scientist is to help venture capitalists with the decision regarding which company they should invest in, by using the information provided in the CSV file. There are five columns, each stating how much during the year company spent for Research & Development, Administration, Marketing, in which state the company is located and the profit of the company.
| R&D Spend | Administration | Marketing Spend | State | Profit |
|
165349.2 |
136897.8 |
471784.1 |
New York |
192261.83 |
|
162597.7 |
151377.59 |
443898.53 |
California |
191792.06 |
|
153441.51 |
101145.55 |
407934.54 |
Florida |
191050.39 |
|
144372.41 |
118671.85 |
383199.62 |
New York |
182901.99 |
|
142107.34 |
91391.77 |
366168.42 |
Florida |
166187.94 |
|
131876.9 |
99814.71 |
362861.36 |
New York |
156991.12 |
|
134615.46 |
147198.87 |
127716.82 |
California |
156122.51 |
|
130298.13 |
145530.06 |
323876.68 |
Florida |
155752.6 |
|
120542.52 |
148718.95 |
311613.29 |
New York |
152211.77 |
|
123334.88 |
108679.17 |
304981.62 |
California |
149759.96 |
In multiple linear regression we have one dependent variable 



or in a matrix form

where

is 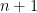
In our case “Profit” is dependent variable and all others and independent variables (columns). Therefore, we can write

In this formula 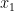



We can add an extra column for each of the states so we will have one column which will have 1 every time New York occurs and zeros for every other state. The second column will have 1 in every row where California appears and zeros everywhere else. The same will happen for Florida. We can see that the column “State” was replaced with 3 other columns/variables, called the dummy variables representing each of the states and now we have 6 columns in total. The first few rows look like this:
| Index | 0 | 1 | 2 | 3 | 4 | 5 |
| 0 | 0 | 0 | 1 | 165349 | 136897 | 471784 |
| 1 | 1 | 0 | 0 | 162597 | 151377 | 443898 |
| 2 | 0 | 1 | 0 | 153441 | 101145 | 407934 |
| 3 | 0 | 0 | 1 | 144372 | 118671 | 383199 |
By replacing categorical data with dummy variables we need to be careful not to fall into the “dummy variable trap”. It is a scenario in which the variables are multicollinear or highly correlated, which means that it is easy to predict one variable from another with very high accuracy (more on Wikipedia). For this reason, we usually don’t include all dummy variables in our model. In this case, we can exclude the first column which is California, because the information about it is contained in the other two columns implicitly.
Let’s see how all of this is done in Python.
First, we need to import libraries which we are going to use and import the CSV file.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
dataset = pd.read_csv('50_Startups.csv')
Now we need to remove the last column “Profit” which is dependent variable and
save all other independent variables (columns) into x.
# Take all columns except the last on which is "Profit" x = dataset.iloc[:, :-1].values # y is the "Profit" column here y = dataset.iloc[:, 4].values
# Transform categorical data ("State") column into numbers
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_x = LabelEncoder()
x[:, 3] = labelencoder_x.fit_transform(x[:, 3])
onehotencoder = OneHotEncoder(categorical_features = [3])
x = onehotencoder.fit_transform(x).toarr
One extra step here is to avoid the dummy variable trap as explained above. The Python linear regression library is already taking care of this so there is no need for us to do it explicitly.
Anyway, to show how it can be done in Python, let’s remove the first column (with index zero) and split the data into training test and test set. Usually, data is split such as between 70-80% of a data is in a training set and the rest in the test set. Here we will take 1/3 of data as a size of a test set.
# Remove column zero, take everything else from the first column on x = x[:, 1:] from sklearn.cross_validation import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 1/3, random_state = 0)
Now we are ready to fit multiple linear regression to the training set. We are importing LinearRegression because we are still doing linear regression but on multiple independent variables.
from sklearn.linear_model import LinearRegression regressor = LinearRegression() regressor.fit(x_train, y_train)
We will test this and predict our observations on the test set.
y_pred = regressor.predict(x_test)
Printing out values of y_pred and y_test we get –
y_test: [ 103282.38 144259.4 146121.95 77798.83 191050.39 105008.31 81229.06 97483.56 110352.25 166187.94]
y_pred: [ 103015.20159796 132582.27760815 132447.73845173 71976.09851258 178537.48221051 116161.24230163 67851.69209676 98791.73374689 113969.43533011 167921.06569547 ]
We can see that y_pred is very similar to the y_test which means that our prediction model is correct.
In the next post, I will talk about optimizing the model further using backward elimination.
Resources:
