
Introduction
More data has been created in the last two years than in the entire history of human race and the amount of data keeps growing at the unprecedented rate. The computational power is getting more available and more powerful which allows us to get data very fast. This data is often very noisy, with missing information and high dimensional, which reduces the ability to visualize it. Usually, very few parts of the data provided are useable. To determine which part of data is relevant for us is not an easy task. It is important first to gain a general understanding of data we are dealing with and then to develop quantitative methods to analyze it. This is where topology, a branch of mathematics can be very useful.
Topology is the mathematical study of the shape and its properties that are preserved through continuous deformations, such as twisting and stretching of objects. It goes back to the 17th century and Leohnard Euler’s paper on the Seven Bridges of Königsberg is regarded as one of the first practical applications of topology.
Topological Data Analysis (TDA) is an area of mathematics which uses techniques from topology to analyze data sets. The idea is to reduce large data sets of many dimensions to smaller dimensions without losing the most relevant topological properties.
The first thing we want to know about data is its overall structure or shape. For example, the simplest way of representing data is with a line and linear regression. But, our data representations are usually much more complicated. Another example of a shape of data is a cluster.

Example of a Cluster, taken from https://www.ayasdi.com/blog/machine-intelligence/why-topological-data-analysis-can-deal-with-complex-data/
Mathematically, the dataset is a finite metric space. We can represent it as a matrix, usually in a spreadsheet, where rows represent data points and columns represent features or dimensions. We can see that when we have a CSV table that we can put Euclidean or similar distances on it. In general, for other Machine Learning techniques, the similarity between data points needs to be very high. In TDA, we can use any notion of similarity to achieve good results so we can say that the TDA is more general, which is its advantage.
In a data set, many different shapes can appear which means that we can’t deal with each of the shapes on its own but we need a generalization. The shape of data is usually defined in terms of a metric – Euclidean, Hamming, correlation distance, etc.
We will consider points that are close to each other very similar, while points that are far from each other are not considered similar. We can extract every row from the table as a single point in a point cloud and we define distance as follows
Definition: Distance function of a cloud For a compact set (a cloud),

define


as the distance from

to the closest point from the set

There are few key properties in topology that make possible extraction of features from data.
- Topology studies properties of geometric objects which don’t depend on the coordinate frame in which they are represented. This allows us to compare data from different coordinate systems (different sources).
- Topology studies properties of curves and surfaces which do not change when you ‘stretch’ them.
This means that the surface of a mug can be continuously deformed into a torus (they are topologically equivalent).

Deforming mug into a torus
A basic building block in topology is n-simplex. A few basic simplexes are:
- 0-simplex : a point
- 1-simplex : a closed interval
- 2-simplex : a triangle
- 3-simplex : a tetrahedron
In general, 
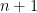
We can represent a shape using triangulation, which means that we can identify a shape with simplicial complex or a network. Simplicial complex in computational geometry is a set of triangles ‘glued’ together. For example, we can approximate a lake with a polygon, i.e. we can replace a set of data points with the family of simplicial complexes and convert data sets into topological objects.
Definition: Triangulation of Topological Space 


A triangulation is a homeomorphism between a topological space and a Euclidean simplicial complex.
We can think of a point cloud space as a manifold in a topological space and a simplicial complex is an approximation of the manifold. Our goal is to create complexes from a point cloud by connecting points which can give us many possible complexes. The problem is how to find the complex that accurately reflects the topological properties of the object from which the sample originated and persistent homology is dealing with this problem.

A sensor observing an annulus producing a sample of points. Three possible complexes that may be formed from the sample are shown. Only the leftmost complex provides a reasonable approximation of the underlying annulus. The image and the footnote are taken from “Kairui Glen Wang – The Basic Theory of Persistent Homology”.
In the next post, I will talk about persistent homology and its connections with TDA. Also, I will show why TDA works better than, for example, principal component analysis (PCA) method.
Resources:
- http://math.uchicago.edu/~womp/2004/athomas04.pdf
- https://en.wikipedia.org/wiki/Nerve_of_a_covering
- https://en.wikipedia.org/wiki/Cover_(topology)#open_cover
- https://www.youtube.com/watch?v=iOxLgbnl1u4
- http://www.dyinglovegrape.com/math/topology_data_1.php
- https://www.math.upenn.edu/~ghrist/preprints/barcodes.pdf
- https://www.ayasdi.com/blog/bigdata/why-topological-data-analysis-works/
